Abstract
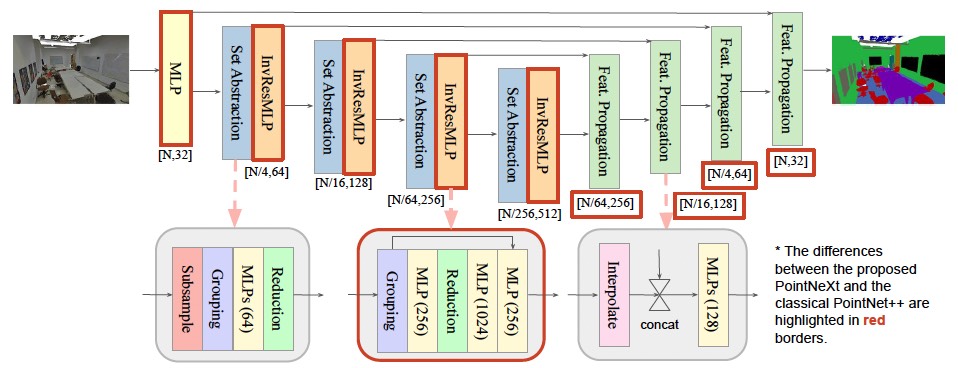
PointNet++ is one of the most influential neural architectures for point cloud understanding. Although its accuracy has been surpassed by recent networks such as PointMLP and Point Transformer, we find that much of the performance gain comes from improved training strategies, data augmentation, optimization techniques, and increased model sizes rather than architectural innovations alone. We revisit PointNet++ through a systematic study of training and scaling strategies. First, we propose improved training strategies that significantly boost PointNet++ performance, raising overall accuracy on ScanObjectNN from 77.9% to 86.1% without architectural changes. Second, we introduce an inverted residual bottleneck design and separable MLPs into PointNet++ to enable efficient scaling, yielding PointNeXt. PointNeXt can be flexibly scaled and achieves strong results on 3D classification and segmentation tasks.